在服务端的开发过程中,我们经常需要完成 复杂数据结构 <--> 二进制数据 之间的序列化、反序列化操作。
与易于阅读的Json相比,Google Protocol Buffers是一个不错的选择。然而,其速度依然比较慢。去年,Google又开源了推出了一款序列化利器:Google FlatBuffers。本文将简介其用法,
1、为什么要用Google FlatBuffers
我就不用复杂的文字描述了,一份官方Benchmark数据就足以说明问题:
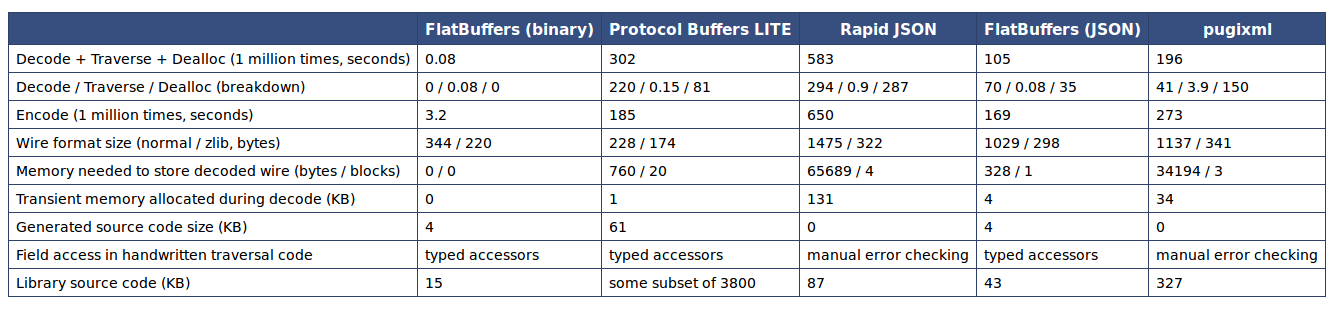 可以看到,与Protocol Buffers相比,尽管FlatBuffers在空间使用上不具有优势,但是反序列化上的性能非常彪悍!
可以看到,与Protocol Buffers相比,尽管FlatBuffers在空间使用上不具有优势,但是反序列化上的性能非常彪悍!
为什么这么高效呢,援引官方的文档:
- 对序列化数据的访问不需要打包和拆包——它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而没有任何解析开销;(这是最主要的原因,ProtoBuffer、JSON等均需要拆包和解包)
- 内存效率和速度——访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配。 这里可查看详细的基准测试;
- 扩展性、灵活性——它支持的可选字段意味着不仅能获得很好的前向/后向兼容性(对于长生命周期的游戏来说尤其重要,因为不需要每个新版本都更新所有数据);
- 最小代码依赖——仅仅需要自动生成的少量代码和一个单一的头文件依赖,很容易集成到现有系统中。再次,看基准部分细节;
- 强类型设计——尽可能使错误出现在编译期,而不是等到运行期才手动检查和修正;
- 使用简单——生成的C++代码提供了简单的访问和构造接口;而且如果需要,通过一个可选功能可以用来在运行时高效解析Schema和类JSON格式的文本;
- 跨平台——支持C++11、Java,而不需要任何依赖库;在最新的gcc、clang、vs2010等编译器上工作良好;
2、编译&安装
可以在github上找到最新的release版本:https://github.com/google/flatbuffers/releases
wget https://github.com/google/flatbuffers/archive/v1.0.3.zip unzip ./v1.0.3.zip cd flatbuffers-1.0.3/ cmake -DCMAKE_INSTALL_PREFIX:PATH=/home/coder4/soft/flatbuffers -G "Unix Makefiles" make && make install
编译完毕的库和include就在中了。
和protobuffer类似,我们自己开发时候并不需要链接其他lib,只要include和生成的代码就可以了。
最有用的是bin/flatc,这个是编译schema、生成代码的程序。
3、编写自定义Schema
只有schema确定,才能保证序列化、反序列化的高性能(因为会生成裸代码,比json等动态执行的要高效很多)
我们构造一个如下的Schema文件 test.fb
namespace TestApp;
struct KV {
key: ulong;
value: double;
}
table TestObj {
id:ulong;
name:string;
flag:ubyte = 0;
list:[ulong];
kv:KV;
}
root_type TestObj;
简单解释一下,FlatBuffer,支持的数据结构有:基本类型和复杂类型。
基本类型:
- 8 bit: byte ubyte bool
- 16 bit: short ushort
- 32 bit: int uint float
- 64 bit: long ulong double
复杂类型:
- 数组 (用中括号表示
[type]). 不支持嵌套数组,可以用table实现 字符串 string, 支持 UTF-8 或者 7-bit ASCII. 对于其他编码可以用数组 [byte]或者[ubyte]表示。- Struct 只支持基本类型或者嵌套Struct
- Table 类似Struct,但是可以支持任何类型。
看完这些,大家应该就很清楚上面的fb是怎么生成的啦。
KV是一个Struct,有2个名为key和value的变量。
TestObj是一个Table,包含了KV的成员、list数组、flag的uint8(初始值0)、以及uint64的id。
最后定义了根入口是TestObj,这句一定要有,否则无法反序列化。
4、编译Schema
执行:
./bin/flatc -c -b ./test.fb
会生成一个.h文件:
test_generated.h
5、序列化、反序列化
#include "test_generated.h"
#include <vector>
#include <iostream>
using namespace std;
using namespace TestApp;
int main()
{
flatbuffers::FlatBufferBuilder builder;
/////////// Serialize //////////
// Create list
std::vector<uint64_t> vec;
for(size_t i=0;i<10;i++)
{
vec.push_back(i);
}
// Create flat buffer inner type
auto id = 123;
auto name = builder.CreateString("name");
auto list = builder.CreateVector(vec); // vector
auto flag = 1;
auto kv = KV(1, 1.0); // struct
// table
auto mloc = CreateTestObj(builder, id, name, flag, list, &kv);
builder.Finish(mloc);
char* ptr = (char*)builder.GetBufferPointer();
uint64_t size = builder.GetSize();
////////// Deserialize //////////
auto obj = GetTestObj((uint8_t*)ptr);
cout << obj->id() << endl;
cout << obj->name()->c_str() << endl;
cout << obj->flag() << endl;
for(size_t i=0;i<obj->list()->size();i++)
{
cout << obj->list()->Get(i) << endl;
}
// can use assign to std::vector for speed up
// vec.reserve(obj->list()->size());
// vec.assign(obj->list()->begin(), obj->list()->end());
cout << obj->kv()->key() << endl;
cout << obj->kv()->value() << endl;
}
由于FlatBuffers使用了c++0x的特性,所以编译必须使用支持c++0x的版本,例如
g++ -std=c++0x ./test.cpp -I ./include/
对代码说明如下:
- 由于FlatBuffer中的类型小复杂,且官方也没有给出明确的例子,所以我就偷懒用了auto特性。处女座请自行参阅源代码。
- 基础类型直接赋值,符合类型需要用FlatBufferBuilder.CreateXXX,例如String和Vector
- Struct类型,直接构造
- Table类型,用CreateXXX,其中XXX为定义的类型,这个在生成代码的.h中
- 序列化时候,可以直接从Builder取出指针和length,然后就可以塞入string啦~
- 反序列化的时候,注意所有成员都需要用函数()而不是直接使用成员名。
小结一下,生成的代码还真是小乱,用法五花八门,为了性能就忍忍吧,用习惯就好了。
最后说一句,FlatBuffer还支持其他更为高级的用法,例如直接反序列化为Json/从Json序列化,但是性能比较慢,大家慢慢探索吧。
11122
sad