https://cloud.tencent.com/developer/article/1136054
很多的to_bitmap都是用这个数据结构实现的

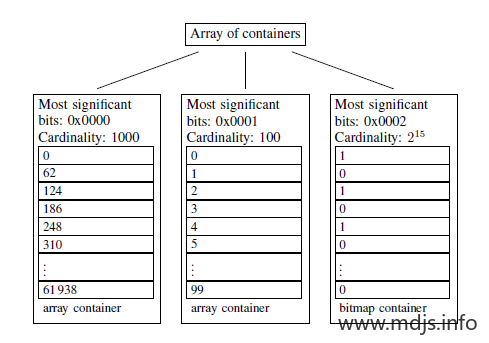 [......]
[......]
https://www.infoq.cn/article/fjebconxd2sz9wloykfo[......]
https://developer.huawei.com/consumer/cn/forum/topic/0202775562683000448[......]
format_datetime(current_date, 'YYYY-MM-dd'),
format_datetime(DATE_ADD('day', -1, current_date), 'YYYY-MM-dd')
format_datetime(DATE_ADD('day', -2, current_date), 'YYYY-MM-dd')
[......]
需求:Reduce输出特殊的格式结果
例如:如Reducer的结果,压到Guava的BloomFilter中
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.h[......]