0. 测试环境
阿里云,内存型R5,2核16G内存,5台机器。
RocketMq部署采用Docker,自己定制了镜像,参见:docker-rocketmq
1. 单机测试
单机: NameServer、Broker、Test程序都部署在一台机器上。
1.1 单机 发送线程与TPS
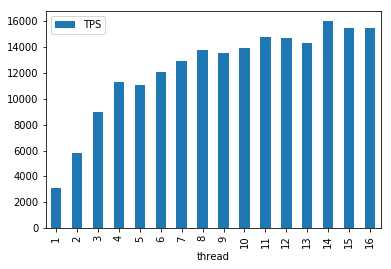
此时默认msgLen=100,主要看线程数的增加,对于同步发消息性能的影响。
可以看到12个线程后,TPS ~= 12K/s,之后线程数再增加,也不会有很大增长了。
我选用的R5机器,只有2个核心,而且应该是有其他隔离限制,所以性能不太高,之后可以换更好的机器再测试。
1.2 单机 消息长度与TPS
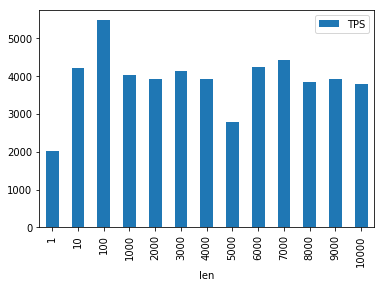
此时固定线程数为8,主要看消息长度的增加,对于同步发消息性能的影响。
这里看到影响不太明显,并且TPS普遍偏低。
分析了下。主要原因是
- 都部署在一台机器上,有一定相互影响
- 当时物理机可能有别人在搞事情,导致资源受限
后面的集群测试,结果比较符合预期。
2. 集群测试
集群测试: 1台ns,3台broker(master only no slave 异步刷盘),打压单独1台
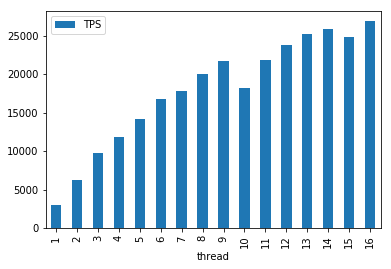
2.1 集群 线程数与TPS
固定30个topic,均匀分布到3台broker上
可以看到,TPS可以打到25k,大概是单机的2倍。
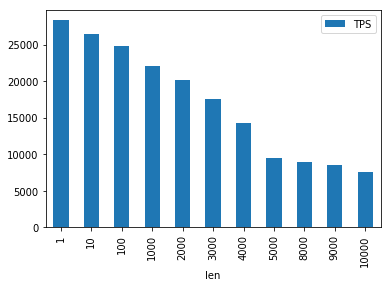
2.2 集群 消息长度与TPS
和上面单机测试相比,集群测试结果符合预期。
即随着消息长度增加,TPS逐渐下降。
对于常见长度(msgLen < 1k),下降不太明显。
2.3 集群 Topic数量与TPS
测试topic数量对同步发消息的影响。
500个topic平均分配到3台broker上。
结论是至少在500个Topic内,没有太大影响。

打压程序用Java写的,放到了github上,perf-rocketmq,供参考。
另外,我这里用的阿里云ECS,性能难免受限,各位感兴趣,可以用更好的机器测一下。
欢迎汇报更好的测试结果。
附原始打压数据:
# 单机打压 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=1, TPS=3117.40 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=2, TPS=5822.08 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=3, TPS=8973.44 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=4, TPS=11280.32 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=5, TPS=11092.62 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=6, TPS=12068.55 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=7, TPS=12909.89 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=8, TPS=13768.42 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=9, TPS=13579.58 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=10, TPS=13952.84 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=11, TPS=14817.01 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=12, TPS=14699.40 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=13, TPS=14324.60 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=14, TPS=16033.35 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=15, TPS=15482.27 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=16, TPS=15494.27 Sync Send Test 1k, len=1, topicCnt=1, threadCnt=8, TPS=2008.03 Sync Send Test 1k, len=10, topicCnt=1, threadCnt=8, TPS=4219.41 Sync Send Test 1k, len=100, topicCnt=1, threadCnt=8, TPS=5464.48 Sync Send Test 1k, len=1000, topicCnt=1, threadCnt=8, TPS=4016.06 Sync Send Test 1k, len=2000, topicCnt=1, threadCnt=8, TPS=3921.57 Sync Send Test 1k, len=3000, topicCnt=1, threadCnt=8, TPS=4132.23 Sync Send Test 1k, len=4000, topicCnt=1, threadCnt=8, TPS=3906.25 Sync Send Test 1k, len=5000, topicCnt=1, threadCnt=8, TPS=2770.08 Sync Send Test 1k, len=6000, topicCnt=1, threadCnt=8, TPS=4237.29 Sync Send Test 1k, len=7000, topicCnt=1, threadCnt=8, TPS=4405.29 Sync Send Test 1k, len=8000, topicCnt=1, threadCnt=8, TPS=3846.15 Sync Send Test 1k, len=9000, topicCnt=1, threadCnt=8, TPS=3921.57 Sync Send Test 1k, len=10000, topicCnt=1, threadCnt=8, TPS=3773.58
# 集群情况 DefaultCluster broker2 0 192.168.6.87:10911 V4_3_2 0.00(0,0ms) 0.00(0,0ms) 0 431625.93 -1.0000 DefaultCluster broker3 0 192.168.6.86:10911 V4_3_2 0.00(0,0ms) 0.00(0,0ms) 0 431625.93 -1.0000 DefaultCluster broker4 0 192.168.6.89:10911 V4_3_2 0.00(0,0ms) 0.00(0,0ms) 0 431625.93 -1.0000 # 集群打压 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=1, TPS=2593.43 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=2, TPS=6069.80 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=3, TPS=9349.29 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=4, TPS=11674.06 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=5, TPS=14432.10 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=6, TPS=16414.97 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=7, TPS=18463.81 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=8, TPS=18811.14 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=9, TPS=18775.82 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=10, TPS=22836.26 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=11, TPS=22466.86 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=12, TPS=22381.38 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=13, TPS=25025.03 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=14, TPS=25588.54 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=15, TPS=26055.24 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=16, TPS=27173.91 Sync Send Test 100k, len=1, topicCnt=30, threadCnt=16, TPS=28074.12 Sync Send Test 100k, len=10, topicCnt=30, threadCnt=16, TPS=26709.40 Sync Send Test 100k, len=100, topicCnt=30, threadCnt=16, TPS=23105.36 Sync Send Test 100k, len=1000, topicCnt=30, threadCnt=16, TPS=22366.36 Sync Send Test 100k, len=2000, topicCnt=30, threadCnt=16, TPS=18129.08 Sync Send Test 100k, len=3000, topicCnt=30, threadCnt=16, TPS=16949.15 Sync Send Test 100k, len=4000, topicCnt=30, threadCnt=16, TPS=15494.27 Sync Send Test 100k, len=5000, topicCnt=30, threadCnt=16, TPS=10243.80 Sync Send Test 100k, len=6000, topicCnt=30, threadCnt=16, TPS=10817.83 Sync Send Test 100k, len=7000, topicCnt=30, threadCnt=16, TPS=10139.93 Sync Send Test 100k, len=8000, topicCnt=30, threadCnt=16, TPS=9321.40 Sync Send Test 100k, len=9000, topicCnt=30, threadCnt=16, TPS=8646.03 Sync Send Test 100k, len=10000, topicCnt=30, threadCnt=16, TPS=7697.64 Sync Send Test 100k, len=100, topicCnt=1, threadCnt=8, TPS=10423.18 Sync Send Test 100k, len=100, topicCnt=50, threadCnt=8, TPS=14300.01 Sync Send Test 100k, len=100, topicCnt=100, threadCnt=8, TPS=18083.18 Sync Send Test 100k, len=100, topicCnt=150, threadCnt=8, TPS=17361.11 Sync Send Test 100k, len=100, topicCnt=200, threadCnt=8, TPS=18446.78 Sync Send Test 100k, len=100, topicCnt=250, threadCnt=8, TPS=16714.02 Sync Send Test 100k, len=100, topicCnt=300, threadCnt=8, TPS=18674.14 Sync Send Test 100k, len=100, topicCnt=350, threadCnt=8, TPS=16691.70 Sync Send Test 100k, len=100, topicCnt=400, threadCnt=8, TPS=18597.73 Sync Send Test 100k, len=100, topicCnt=450, threadCnt=8, TPS=18178.51 Sync Send Test 100k, len=100, topicCnt=500, threadCnt=8, TPS=17733.64