1 部署Kubernetes集群
这里简化用minikube替代
minikube start --image-mirror-country='cn' --image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers'
2 下载最新版的prometheus operator
发布地址:这里
3 部署operator
unzip kube-prometheus-0.9.0.zip cd kube-prometheus-0.9.0 kubectl apply --server-side -f manifests/setup until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done kubectl apply -f manifests/
等一会儿,部署好的效果如下,关键的pod都需要是Run状态:
kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-6f6b8cc4f6-r87qj 1/1 Running 0 21m kube-system etcd-minikube 1/1 Running 0 21m kube-system kube-apiserver-minikube 1/1 Running 0 21m kube-system kube-controller-manager-minikube 1/1 Running 0 21m kube-system kube-proxy-58rd5 1/1 Running 0 21m kube-system kube-scheduler-minikube 1/1 Running 0 21m monitoring alertmanager-main-0 2/2 Running 0 5m53s monitoring alertmanager-main-1 2/2 Running 0 5m53s monitoring alertmanager-main-2 2/2 Running 0 5m53s monitoring blackbox-exporter-6798fb5bb4-t9vgw 3/3 Running 0 5m52s monitoring grafana-7476b4c65b-6qhwj 1/1 Running 0 5m51s monitoring kube-state-metrics-74964b6cd4-ntvqz 3/3 Running 0 5m50s monitoring node-exporter-72jws 2/2 Running 0 5m50s monitoring prometheus-adapter-5b8db7955f-br76d 1/1 Running 0 5m50s monitoring prometheus-adapter-5b8db7955f-vngbj 1/1 Running 0 5m50s monitoring prometheus-k8s-0 2/2 Running 0 5m49s monitoring prometheus-k8s-1 2/2 Running 0 5m49s monitoring prometheus-operator-75d9b475d9-8vhwm 2/2 Running 0 7m13s
说下上面重点的一些Pod:
- node-exporter:节点指标监控,几个节点就有几个
- kube-state-metrics:k8s集群本身的状态监控
- prometheus-k8s:prometheus服务进程,默认2台
- alartmanager-main:报警,默认3台
- grafana:图表Web,默认1台
4 查看Grafana
这里简单用port-forward,针对线上你可以用node port,或者ingress
kubectl port-forward grafana-7476b4c65b-6qhwj -n monitoring 3000:3000
打开浏览器:
http://127.0.0.1:3000
默认用户名和密码都是admin
进入后,能看到指标采集已经正常工作了,如下图所示: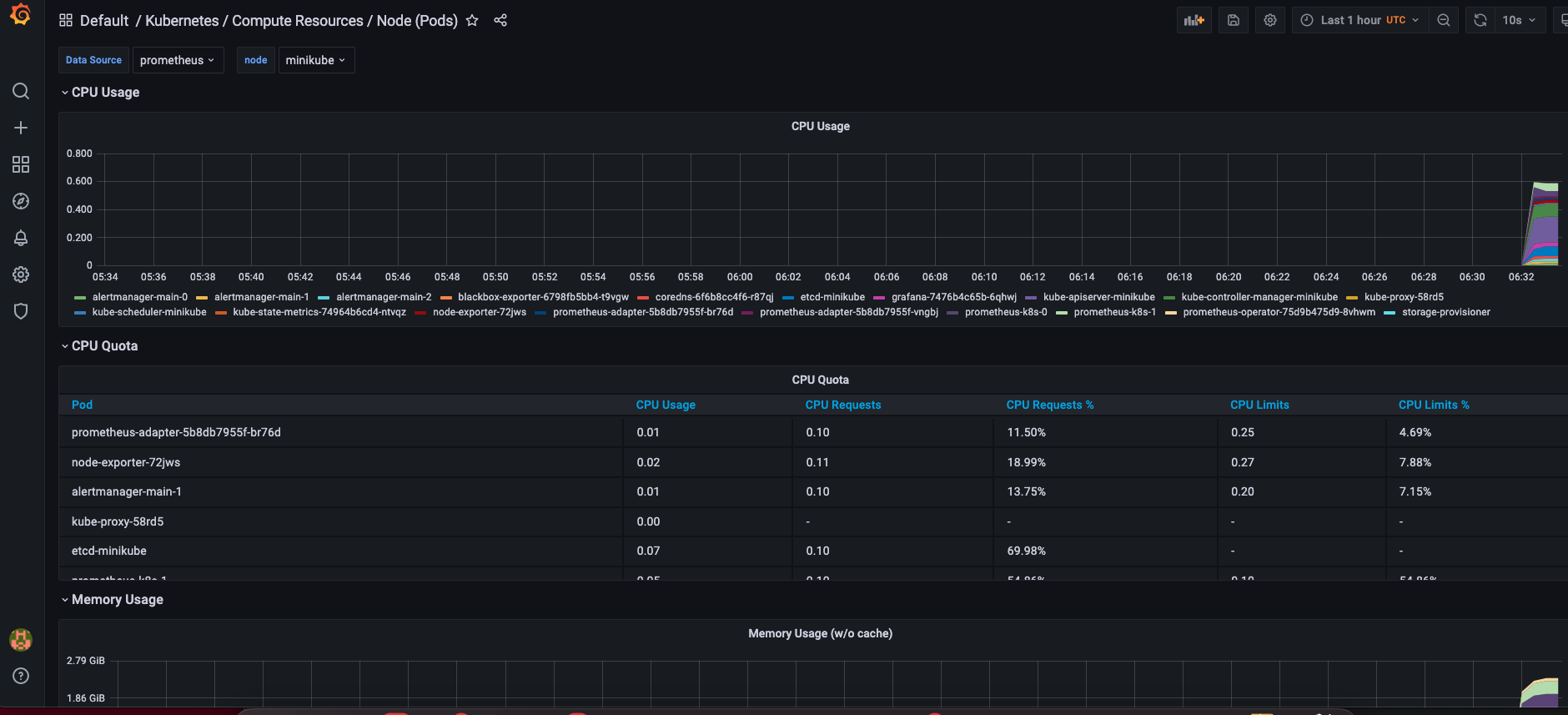
5 应用服务自定义指标
在实际工作中,我们不可能只监控Kubernetes集群的基本指标
我们需要的是应用内部的指标,这些需要采用自定义的方式完成
我们首先模拟一个服务端的自定义指标,这里用官方的go例子:
package main
import (
"net/http"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func recordMetrics() {
go func() {
for {
opsProcessed.Inc()
time.Sleep(5 * time.Second)
}
}()
}
var (
opsProcessed = promauto.NewCounter(prometheus.CounterOpts{
Name: "myapp_processed_ops_total",
Help: "The total number of processed events",
})
)
func main() {
recordMetrics()
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":2222", nil)
}
接着,我们打包,将它变成一个Docker Hub上的镜像,这里省略步骤了,我把代码和Dockerfile放到了github的go-prometheus-metrics-docker项目中,请自行查阅。
如果你只是想试试,可以用我打好的镜像(DockerHub)coder4/go-prometheus-metrics:latest
6 启动应用服务
我们用Deployment的方式部署到k8s集群,如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: gmm
labels:
app: gmm
spec:
replicas: 2
selector:
matchLabels:
app: gmm
template:
metadata:
labels:
app: gmm
tier: backend
spec:
containers:
- name: gmm
image: coder4/go-prometheus-metrics:latest
ports:
- name: web
containerPort: 2222
这里有一些关键点:
- labels的tier是backend,后面监控选取pod时会用到
- ports的name,需要做成一个命名port,后面会用到
7 部署PodMonitor
实际上,使用Operator后,你可以选用ServiceMonitor或PodMonitor,这里选了后者,更多配置选项可以看官方文档。
PodMonitor部署如下:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: pod-monitor-backend
namespace: monitoring
spec:
selector:
matchLabels:
tier: backend
namespaceSelector:
matchNames:
- default
podMetricsEndpoints:
- port: web
path: /metrics
解释下:
- selector的matchLabels,匹配了所有tier为backend的Pod
- namespaceSelector设定了要从那个ns下查找,默认是和PodMonitor相同的
- podMetricsEndPoints的port是个名字,不是端口!要和Pod中的定义对的上,path是自定义的路径
部署成功后,稍等一会(默认30秒刷新),我们启动下Prometues的UI(不是grafana了)
kubectl port-forward prometheus-k8s-0 -n monitoring 9090:9090
然后查看Targets,就能发现,已经成功在抓取目标了!
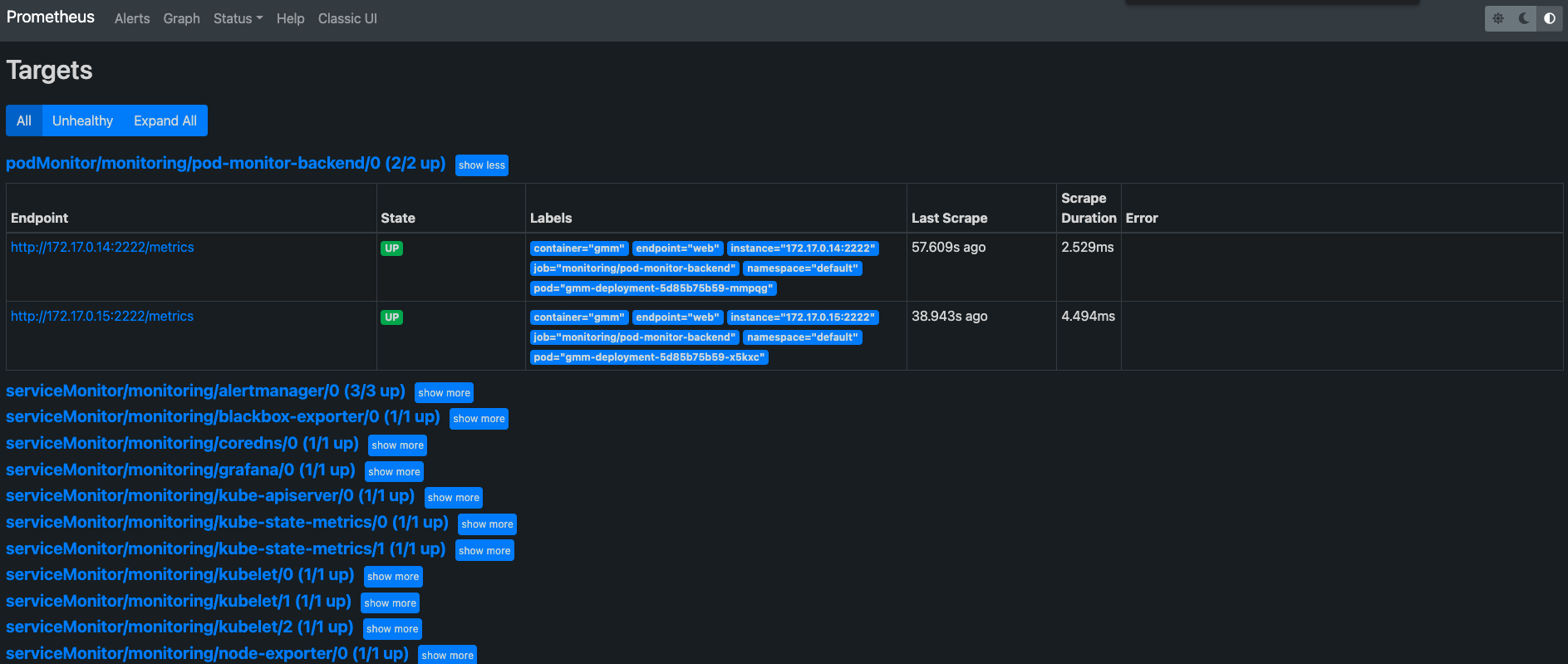
接下来,你可以按照PromeQL的语法,把它配置到Grafana的报表中,这里就不在赘述了。
如果Target没有成功出现,你可以在如下地址分别查看配置,一般就能定位问题了:
- 首先确认时间是否足够,一般要等30秒以上
- http://127.0.0.1:9090/config:看一下config中是否有
- http://127.0.0.1:9090/service-discovery:看一下匹配情况,一般是label没写对