HuggingFace的transformers库提供了各种SOTA开源模型的方案,而且做了整合链,很方便使用。
1 安装
pip install transformers
2 做情感分析任务
数据准备
from transformers import pipeline
import numpy as np
import pandas as pd
import seaborn as sn
# prepare data
df = pd.read_csv("AirlineTweets.csv")
df.head()
# df has only 3 fields target / airline_sentiment / text
df = df[["airline_sentiment", "text"]].copy()
df['airline_sentiment'].hist()
df = df[df.airline_sentiment != 'neutral'].copy()
target_map = {'positive': 1, 'negative': 0}
df['target'] = df['airline_sentiment'].map(target_map)
df.head()
texts = df['text'].tolist()
模型直接跑不做训练
import torch
from transformers import pipeline
# zero shot classifier single case
print(classifier("This is such a great moive"))
print(classifier("This is moive is a shit"))
# batch process
torch.cuda.is_available()
torch.cuda.current_device()
classifier = pipeline("sentiment-analysis", device=0)
predictions = classifier(texts)
看结果
from sklearn.metrics import
from sklearn.metrics import accuracy_score, f1_score, confusion_matrix
probs = [d['score'] if d['label'].startswith('P') else 1 - d['score'] for d in predictions]
preds = [1 if d['label'].startswith('P') else 0 for d in predictions]
preds = np.array(preds)
print("acc:", accuracy_score(df['target'], preds))
print("f1_score:", f1_score(df['target'], preds))
默认的模型是distilbert,以上完全是没有任何训练的,直接zero shot效果很强:
- acc: 0.8898708950697514
- f1_score: 0.7587777566900741
3 pipeline支持的其他任务类型
参见文档
- "audio-classification": will return a AudioClassificationPipeline.
- "automatic-speech-recognition": will return a AutomaticSpeechRecognitionPipeline.
- "conversational": will return a ConversationalPipeline.
- "depth-estimation": will return a DepthEstimationPipeline.
- "document-question-answering": will return a DocumentQuestionAnsweringPipeline.
- "feature-extraction": will return a FeatureExtractionPipeline.
- "fill-mask": will return a FillMaskPipeline:.
- "image-classification": will return a ImageClassificationPipeline.
- "image-segmentation": will return a ImageSegmentationPipeline.
- "image-to-image": will return a ImageToImagePipeline.
- "image-to-text": will return a ImageToTextPipeline.
- "mask-generation": will return a MaskGenerationPipeline.
- "object-detection": will return a ObjectDetectionPipeline.
- "question-answering": will return a QuestionAnsweringPipeline.
- "summarization": will return a SummarizationPipeline.
- "table-question-answering": will return a TableQuestionAnsweringPipeline.
- "text2text-generation": will return a Text2TextGenerationPipeline.
- "text-classification" (alias "sentiment-analysis" available): will return a TextClassificationPipeline.
- "text-generation": will return a TextGenerationPipeline:.
- "text-to-audio" (alias "text-to-speech" available): will return a TextToAudioPipeline:.
- "token-classification" (alias "ner" available): will return a TokenClassificationPipeline.
- "translation": will return a TranslationPipeline.
- "translation_xx_to_yy": will return a TranslationPipeline.
- "video-classification": will return a VideoClassificationPipeline.
- "visual-question-answering": will return a VisualQuestionAnsweringPipeline.
- "zero-shot-classification": will return a ZeroShotClassificationPipeline.
- "zero-shot-image-classification": will return a ZeroShotImageClassificationPipeline.
- "zero-shot-audio-classification": will return a ZeroShotAudioClassificationPipeline.
- "zero-shot-object-detection": will return a ZeroShotObjectDetectionPipeline.
4 做文本生成任务
使用默认的gpt2:
from transformers import pipeline
import textwrap
import numpy as np
import matplotlib.pyplot as plt
from pprint import pprint
# lines that are not empty
lines = [line.rstrip() for line in open('robert_frost.txt')]
lines = [line for line in lines if len(line) > 0]
lines[0]
# default gpt2
gen = pipeline('text-generation')
gen(lines[0])
gen(lines[0], max_length=128)
有点胡乱说,效果一般:
[{'generated_text': 'Two roads diverged in a yellow wood, where trees were planted. Then the bridge over the Mississippi reached me. I turned the corner so that the bridge would come down behind me. I pushed hard on it. The bridge slipped and fell from me and me, and I came from a distance of five or six steps below. The bridge was not strong enough to keep me out of the water, and I got out of there. On that second day, I went to the Mississippi town-hall and there heard some people talking about the Great Flood. They had all talked about the Mississippi being the cause of such a great flood, but'}]
换成最近风很大的Mistral-7B,这个需求内存很大需要用A100:
这里让他生成3次
from transformers import pipeline
import textwrap
import numpy as np
import matplotlib.pyplot as plt
from pprint import pprint
# lines that are not empty
lines = [line.rstrip() for line in open('robert_frost.txt')]
lines = [line for line in lines if len(line) > 0]
lines[0]
gen = pipeline('text-generation', model='mistralai/Mistral-7B-Instruct-v0.2')
pprint(gen(lines[0], num_beams=5, num_return_sequences=3, max_length=256))
结果很可以了,真伪难分(不知道有没有数据污染):
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
[{'generated_text': 'Two roads diverged in a yellow wood,\n'
'And sorry I could not travel both\n'
'And be one traveler, long I stood\n'
'And looked down one as far as I could\n'
'To where it bent in the undergrowth;\n'
'\n'
'Then took the other, as just as fair,\n'
'And having perhaps the better claim,\n'
'Because it was grassy and wanted wear;\n'
'Though as for that the passing there\n'
'Had worn them really about the same,\n'
'\n'
'And both that morning equally lay\n'
'In leaves no step had trodden black.\n'
'\n'
'Oh, I kept the first for another day!\n'
'Yet knowing how way leads on,\n'
'I doubted if I should ever come back.\n'
'\n'
'I shall be telling this with a sigh\n'
'Somewhere ages and ages hence:\n'
'Two roads diverged in a wood, and I—\n'
'I took the one less traveled by,\n'
'And that has made all the difference.\n'
'\n'
'Robert Frost (1874-1963)'},
{'generated_text': 'Two roads diverged in a yellow wood,\n'
'And sorry I could not travel both\n'
'And be one traveler, long I stood\n'
'And looked down one as far as I could\n'
'To where it bent in the undergrowth;\n'
'\n'
'Then took the other, as just as fair,\n'
'And having perhaps the better claim,\n'
'Because it was grassy and wanted wear;\n'
'Though as for that the passing there\n'
'Had worn them really about the same,\n'
'\n'
'And both that morning equally lay\n'
'In leaves no step had trodden black.\n'
'\n'
'Oh, I kept the first for another day!\n'
'Yet knowing how way leads on,\n'
'I doubted if I should ever come back.\n'
'\n'
'I shall be telling this with a sigh\n'
'Somewhere ages and ages hence:\n'
'Two roads diverged in a wood, and I—\n'
'I took the one less traveled by,\n'
'And that has made all the difference.\n'
'\n'
'Robert Frost (1874-1963)\n'
'\n'
'The Road Not Taken is a poem by Robert Frost, published '
"in 1916. It is one of Frost's most famous works. The poem "
"describes the speaker's"},
{'generated_text': 'Two roads diverged in a yellow wood,\n'
'And sorry I could not travel both\n'
'And be one traveler, long I stood\n'
'And looked down one as far as I could\n'
'To where it bent in the undergrowth;\n'
'\n'
'Then took the other, as just as fair,\n'
'And having perhaps the better claim,\n'
'Because it was grassy and wanted wear;\n'
'Though as for that the passing there\n'
'Had worn them really about the same,\n'
'\n'
'And both that morning equally lay\n'
'In leaves no step had trodden black.\n'
'\n'
'Oh, I kept the first for another day!\n'
'Yet knowing how way leads on,\n'
'I doubted if I should ever come back.\n'
'\n'
'I shall be telling this with a sigh\n'
'Somewhere ages and ages hence:\n'
'Two roads diverged in a wood, and I—\n'
'I took the one less traveled by,\n'
'And that has made all the difference.\n'
'\n'
'Robert Frost (1874-1963)\n'
'\n'
'The Road Not Taken is a poem by Robert Frost, published '
"in 1916. It is one of Frost's best-known works, and is "
'almost universally recognized'}]
再生成论文,直接拼成全文了:
def wrap(x):
return textwrap.fill(x, replace_whitespace=False, fix_sentence_endings=True)
prompt = "Neural networks with attention have been used with great success" + \
" in natural language processing."
gen = pipeline('text-generation', model='mistralai/Mistral-7B-Instruct-v0.2')
out = gen(prompt, max_length=300)
print(wrap(out[0]['generated_text']))
结果:
## 1. Introduction Image captioning is the task of generating a natural language description of an image. It is a challenging problem that requires understanding the visual content of an image and generating a coherent and descriptive sentence. Image captioning has applications in various domains, such as e-commerce, multimedia search engines, and accessibility for visually impaired people. Traditional approaches to image captioning relied on hand-crafted features and template-based methods. However, these methods were limited in their ability to capture the complex relationships between visual and linguistic information. With the advent of deep learning, neural networks have become the dominant approach for image captioning. Convolutional neural networks (CNNs) have been used for feature extraction from images, while recurrent neural networks (R
5 Huggingface使用私有模型(比如llma2)
需要先登录
!huggingface-cli login
然后输入你在huggingface设置的token就可以了
6 使用GPTQ量化模型
使用大模型有个问题是需要的GPU内存太大,可以选用GPTQ量化方法精简后的模型
比如TheBloke大佬的帐号下,有大量这种模型,主流的开源模型都有gptq的版本,像极了PT站上的压片组:-)
我们用T4的16G内存跑13B模型
需要一些额外安装:
!pip install optimum !pip install auto-gptq !pip install -U accelerate bitsandbytes datasets peft transformers
使用GPTQ模型:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Llama-2-13B-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Neural networks with attention have been used with great success" + \
" in natural language processing."
prompt_template=f'''{prompt}
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
速度快了不少,效果也还可以,连markdown格式都弄出来了..
<s> Neural networks with attention have been used with great success in natural language processing.
## Attention
Attention is a mechanism for selecting important information in a stream of information.

## Attention in NLP
Attention is a technique used in NLP to select important information in a stream of information.
It is used to select information from the input sequence that is used in the output sequence.

### Attention in Recurrent Neural Networks (RNNs)
Attention is used in RNNs to select important information in a sequence.

### Attention in Transformer
Attention is used in Transformer to select important information in a sequence.

### Attention in Transformer for NLP
Attention is used in Transformer to select important information in a sequence.

### Attention in NLP
Attention is used in NLP to select important information in a sequence.

### Attention in BERT
Attention is used in BERT to select important information in a sequence.

### Attention in BERT for NLP
Attention is used in BERT to select important information in a sequence.

### Attention in BERT for NLP
Attention is used in BERT to select important information in a sequence.

##
*** Pipeline:
Neural networks with attention have been used with great success in natural language processing.
Neural network models of the brain can be used to understand a wide range of brain disorders such as autism, depression and schizophrenia. The human brain is an extremely complex system comprising 86 billion neurons and trillions of synaptic connections. The study of the human brain is one of the most challenging problems in modern science. This paper presents a novel approach for simulating a neural network model based on the architecture of the brain and its applications in brain disorders.
The rest of this paper is organized as follows: Section~\ref{sec_2} introduces the related work, Section~\ref{sec_3} describes the proposed method, Section~\ref{sec_4} shows the results and finally Section~\ref{sec_5} concludes the paper.
\section{Related Work}\label{sec_2}
In recent years, researchers have focused their efforts on developing neural network-based methods to solve various tasks in medical imaging. A comprehensive review of recent advances in artificial intelligence (AI) for neuroimaging is presented in \cite{gholamian2017deep}. The main focus of this article is on using deep learning techniques for brain disease classification and segmentation. The authors provide a review of different deep learning architectures applied to brain magnetic resonance images (MRI), including convolutional neural networks (CNNs), recurrent neural networks (RNNs), long short term memory (LSTM) networks and generative adversarial networks (GANs). These deep learning architectures are used to classify Alzheimer's disease, Parkinson's disease, multiple sclerosis and other types of brain diseases from MRI data. The authors also discuss the use of deep learning for brain segmentation, which includes segmentation of white matter, gray matter and cerebrospinal fluid. Deep learning has been shown to be effective in detecting small changes in MRI that are difficult to see by humans. However, these methods require large amounts of training data which may not always be available. In addition, it is important to note that deep learning models are often black box systems which makes it difficult to interpret the results obtained from them.
Recently, there has been a surge of interest in using deep learning for understanding the structure and function of the brain at both the macroscopic and microscopic levels.
A few studies have
7 翻译任务
#!pip install transformers sentencepiece transformers[sentencepiece]
# 可能需要重启下colab
eng2spa = {}
for line in open('spa-eng/spa.txt'):
line = line.rstrip()
eng, spa = line.split("\t")
if eng not in eng2spa:
eng2spa[eng] = []
eng2spa[eng].append(spa)
# only subset
eng_phrases = list(eng2spa.keys())
len(eng_phrases)
eng_phrases_subset = eng_phrases[20_000:21_000]
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize('¿Qué me cuentas?'.lower())
print(tokens)
print(sentence_bleu([tokens], tokens))
smoother = SmoothingFunction()
print(sentence_bleu([tokens], tokens, smoothing_function=smoother.method4))
print(sentence_bleu([[1,2,3,4]], [1,2,3,4]))
eng2spa_tokens = {}
for eng, spa_list in eng2spa.items():
spa_list_tokens = []
for text in spa_list:
tokens = tokenizer.tokenize(text.lower())
spa_list_tokens.append(tokens)
eng2spa_tokens[eng] = spa_list_tokens
from transformers import pipeline
translator = pipeline("translation",
model='Helsinki-NLP/opus-mt-en-es', device=0)
translations = translator(eng_phrases_subset)
scores = []
for eng, pred in zip(eng_phrases_subset, translations):
matches = eng2spa_tokens[eng]
# tokenize translation
spa_pred = tokenizer.tokenize(pred['translation_text'].lower())
score = sentence_bleu(matches, spa_pred, smoothing_function=smoother.method4)
scores.append(score)
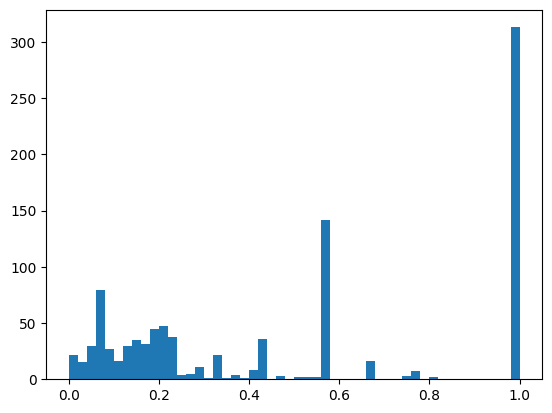
import matplotlib.pyplot as plt
plt.hist(scores, bins=50);
结果:
8 做QA任务
from transformers import pipeline
qa = pipeline("question-answering")
context = "Today I went to the store to purchase a carton of milk."
question = "What did I buy?"
qa(context=context, question=question)
输出:
{'score': 0.5626218318939209,
'start': 38,
'end': 54,
'answer': 'a carton of milk'}
换个模型搞一下中文:
qa = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
context = "阿尔伯特·爱因斯坦(德語:Albert Einstein/ˈalbɛʁt ˈʔaɪnʃtaɪnⓘ,1879年3月14日—1955年4月18日),是出生于德国、拥有瑞士和美国国籍的猶太裔理論物理學家,他创立了現代物理學的兩大支柱的相对论及量子力學[36]:274[1],也是質能等價公式(E = mc2)的發現者[37]。他在科學哲學領域頗具影響力[38][39]。因為“對理論物理的貢獻,特別是發現了光電效應的原理”,他榮獲1921年度的諾貝爾物理學獎(1922年頒發)。這一發現為量子理論的建立踏出了關鍵性的一步。"
question = "爱因斯坦出生在哪里?"
qa(context=context, question=question)
输出:
{'score': 0.88764488697052, 'start': 76, 'end': 78, 'answer': '德国'}
9 微调(语义分析)
准备数据集,并加载为dataset:
!wget -nc https://lazyprogrammer.me/course_files/AirlineTweets.csv
import numpy as np
import pandas as pd
import seaborn as sn
import matplotlib.pyplot as plt
import torch
from sklearn.metrics import f1_score, accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
# raw csv
df_ = pd.read_csv('AirlineTweets.csv')
df = df_[['airline_sentiment', 'text']].copy()
target_map = {'positive': 1, 'negative': 0, 'neutral': 2}
df['target'] = df['airline_sentiment'].map(target_map)
df2 = df[['text', 'target']]
df2.columns = ['sentence', 'label']
df2.to_csv('data.csv', index=None)
# dataset
from datasets import load_dataset
raw_dataset = load_dataset('csv', data_files='data.csv')
split = raw_dataset['train'].train_test_split(test_size=0.3, seed=42)
效果:
DatasetDict({
train: Dataset({
features: ['sentence', 'label'],
num_rows: 10248
})
test: Dataset({
features: ['sentence', 'label'],
num_rows: 4392
})
})
分词,修改下label映射:
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification, AutoConfig, Trainer, TrainingArguments
# tokenize dataset
checkpoint = 'distilbert-base-cased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_fn(batch):
return tokenizer(batch['sentence'], truncation=True)
tokenized_datasets = split.map(tokenize_fn, batched=True)
# modify config label
config = AutoConfig.from_pretrained(checkpoint)
print(config)
print(config.id2label)
config.id2label = {v:k for k, v in target_map.items()}
config.label2id = target_map
print(config.id2label)
加载下修改后的模型:
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, config=config) !pip install torchinfo from torchinfo import summary summary(model)
需要安2个包,可能还要重启下session:
!pip install transformers[torch] !pip install accelerate -U
结果:
training_args = TrainingArguments(
output_dir='training_dir',
evaluation_strategy='epoch',
save_strategy='epoch',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
)
def compute_metrics(logits_and_labels):
logits, labels = logits_and_labels
predictions = np.argmax(logits, axis=-1)
acc = np.mean(predictions == labels)
f1 = f1_score(labels, predictions, average='macro')
return {'accuracy': acc, 'f1': f1}
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
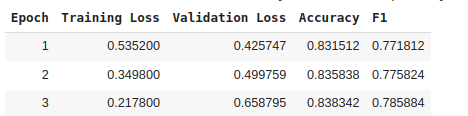
trainer.train()
结果,可以发现有些过拟合了: