之前做过一次RocketMQ打压,但是在资源充足的情况下进行的。
如果我们将RocketMQ部署到弹性云上,在这个资源受限的虚拟机环境中,RoketMQ的性能是多少呢?
1 运行环境
根据之前的《吃土运维指南》我们假设1个核心等于我本地的0.9单核
按照跑分估算,大致相当于阿里云ecs.r5.large(2核16GB)的1核水平
- RocketMQ版本:4.5.2
- Docker镜像:我自己开发的coder4/rocketmq,可以适应不同内存大小(最低512MB)
我们采用docker的cpu、内存限制来进行资源限定
- --cpus 0.9,最多使用0.9个cpu核心
- --memory 1024MB 最多使用1024MB内存,超过会被杀掉
脚本如下:
#!/bin/bash
NAME="rocketmq-broker"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/rocketmq-broker"
VOLUME_LOGS="$VOLUME/logs"
VOLUME_STORE="$VOLUME/store"
mkdir -p $VOLUME_LOGS
mkdir -p $VOLUME_STORE
docker network create nw
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--cpus 0.9 \
--memory 1024M \
--volume "$VOLUME_LOGS":/root/logs \
--volume "$VOLUME_STORE":/root/store \
--env PUID=$PUID \
--env PGID=$PGID \
--env NAMESRV_ADDR="rocketmq-ns:9876" \
-p 10911:10911 \
-p 10909:10909 \
--network nw \
--detach \
--restart always \
coder4/rocketmq:4.5.1 sh mqbroker
以及ns脚本如下:
#!/bin/bash
NAME="rocketmq-ns"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/rocketmq-ns"
VOLUME_LOGS="$VOLUME/logs"
VOLUME_STORE="$VOLUME/store"
mkdir -p $VOLUME_LOGS
mkdir -p $VOLUME_STORE
docker network create nw
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--cpus 0.9 \
--memory 512M \
--volume "$VOLUME_LOGS":/root/logs \
--volume "$VOLUME_STORE":/root/store \
--env PUID=$PUID \
--env PGID=$PGID \
-p 9876:9876 \
--network nw \
--detach \
--restart always \
coder4/rocketmq:4.5.1 sh mqnamesrv
需要指出的是,上面使用的都是我自己修改过的RocketMQ镜像coder4/rocketmq。
这个镜像,进行过小内存参数优化,如果你用官方的镜像,应该没法在4GB以下稳定执行(会被杀掉)
2 打压脚本
我们使用官方的打压脚本,即benchmark下的consumer.sh和producer.sh
在执行前,先设定下NS的ENV:
export NAMESRV_ADDR=localhost:9876
然后打压5分钟
timeout 300 ./producer.sh -w n timeout 300 ./consumer.sh
上面使用n个线程写入消息,然后消费。
3 针对内存受限环境的打压结果
假设CPU = 0.9,写消息线程数为8,我们来看一下在受限内存环境下的TPS
先看生产者:
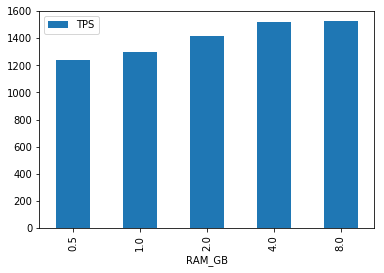
可以发现,随着内存变化,生产者的TPS基本没有明显提升,说明内存并不是瓶颈,即使在512MB的小内存环境下,RocketMQ也可以稳定工作:-)
我们看一下GC情况验证:
broker
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 0.0 1024.0 0.0 1024.0 205824.0 165888.0 20480.0 20404.5 20992.0 20463.6 2304.0 2139.8 47 2.005 0 0.000 2.005
发现broker只发生了47次Yong GC,并且GC总时间刚2秒,不算很严重
ns
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 20224.0 20224.0 0.0 0.0 162240.0 126550.6 64.0 0.0 4480.0 779.0 384.0 74.6 0 0.000 0 0.000 0.000
nameserver则更是一次gc都没有,说明512MB毫无压力
消费者
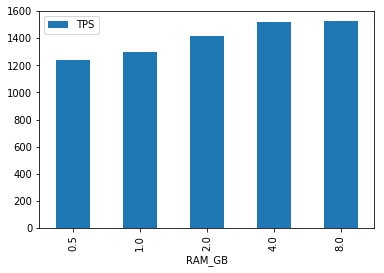
与生产者类似,消费者的TPS页基本稳定在1200 ~ 1600之间,随着内存变化并没有明显提升。
所以针对内存这个环节,我们得出的结论是:
- 对于NameServer,512MB内存足够
- 对于Broker,1GB可以稳定支撑线上运行环境,且不是瓶颈
- 不断提升内存有一点用,但是用处不大。
3 针对cpu受限环境的打压结果
看完了内存,我们再来看一下cpu受限的场景
这次我们固定内存为1GB,写线程到16,调整cpu的限制从0.9 ~ 3.6(大致可以理解为套路云的1核~4核)
生产者
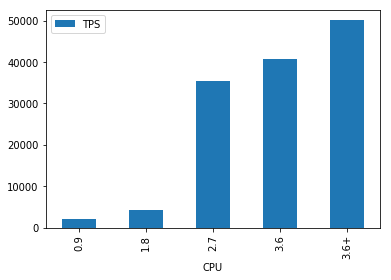
先来看Producer,这个就有点意思了,1核 -> 2核,基本性能翻倍,但是1核到3核后,性能翻了15倍==,再往上,基本就没有线性的性能提升了。
针对这种不太科学的情况,我只能理解为本地docker对多核处理的限制可能有什么bug,导致给了过多的资源。实际在云上的情况,我觉得基本按照1核来翻倍是比较科学的。
这里说一句,3.6+依然是4核,但是写线程加到了32,可以发现,此时还有提升空间,说明性能还可以再往上打的。
消费者
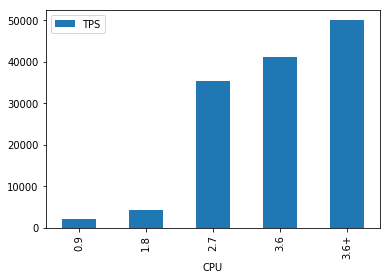 Consumer的情况大体类似,不再赘述。
Consumer的情况大体类似,不再赘述。
写到这里,大家应该发现了,我只提了TPS,没说延迟,这是因为在截至到目前所有的实验中,latency都小于5ms,个别情况(cpu核多时候)基本控制再1ms以下。
这已经是可以直接用于生产的情况了。
针对cpu这个环节,我们得出的结论是:
- 如果想保证性能,尽量多买点计算cpu,比加内存靠谱
- 如果是半个物理机cpu,基本可以干到5W TPS无压力。
4 单核情况极限是多少
其实经常做打压的同学都知道,TPS和延迟是此消彼涨的一对指标,如果只单独看某一个,都是耍流氓。
下面我们来压榨下1核心(0.9 CPU),看看不同写线程数量下的TPS和延迟关系
为了简单起见,我们这里只看Broker的数据
TPS
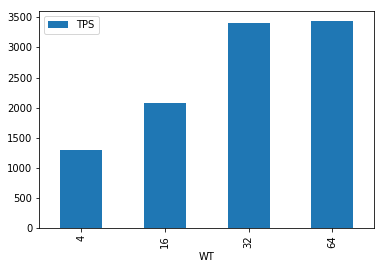
从上图可以发现,当写线程达到32之后,基本就是1核的极限了,再往上加线程也基本没有什么提升,此时TPS大概是3.4K
延迟
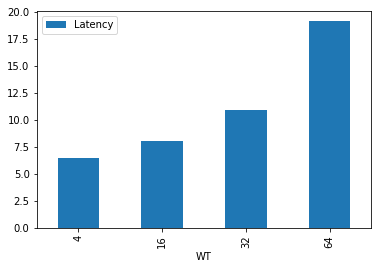
当写线程到达64后,延迟已经接近20ms,这是一个线上消息队列系统的极限了。
所以在这个实验环节,我们可以得出的结论是:1核的broker,最优支撑64并发写,此时TPS是3.4K。
当然再往上加写线程也是可以的,但是延迟会上升,TPS可能并不会有更大提升。
================================================
实验要接近尾声了,细心的你会发现一个问题,本文都是生产者、消费者同时打,如果堆积情况会怎么样呢?
在真实环境中,这种情况一般都取决于消费者的业务逻辑,而消息队列并不是瓶颈,所以我并没有对这种场景进行测试。