Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义。本文对基本用法和常见问题做一个记录。
1、安装
Scrapy虽然是python的模块,但是依赖包比较多,所以我推荐使用apt安装:
sudo apt-get install python-scrapy
编译狂人 或者 处女座 可以从Pypi上下载自行编译安装。友情提示下:pip或者ezsetup上的自动依赖是不全的,需要自己再补其他包。
本文所用的版本是当前最新版[......]
Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义。本文对基本用法和常见问题做一个记录。
1、安装
Scrapy虽然是python的模块,但是依赖包比较多,所以我推荐使用apt安装:
sudo apt-get install python-scrapy
编译狂人 或者 处女座 可以从Pypi上下载自行编译安装。友情提示下:pip或者ezsetup上的自动依赖是不全的,需要自己再补其他包。
本文所用的版本是当前最新版[......]
1.Python中也有像C++一样的默认缺省函数
def foo(text,num=0):
print text,num
foo("asd") #asd 0
foo("def",100) #def 100
定义有默认参数的函数时,这些默认值参数位置必须都在非默认值参数后面。
调用时提供默认值参数值时,使用提供的值,否则使用默认值。
2.Python可以根据参数名传参数
def foo(ip,port)[......]
# 分割符为, file是文件
paste -d, -s file
# 使用管道,分割符为空格
cat file | paste -d " " -s -
如何在Linux中将文件或者stdin的多行合并为1行,如上所示。
[......]
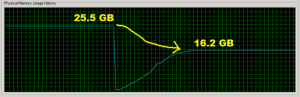
转载自:用Python的 __slots__ 节省9G内存
我们曾经提到,Oyster.com的Python web服务器怎样利用一个巨大的Python dicts(hash table),缓存大量的静态资源。我们最近在Image类中,用仅仅一行 slots 代码,让每个6G内存占用的服务进程(共4个),省出超过2G来。
这是其中一个服务器在部署代码前后的截图:
physical-memory-usage-history
我们alloc了大约一百万个类似如下class的实例:[......]
1. 标准化(Standardize):
标准化给定数据集中所有数值属性(或者分别对每个feature列处理)的值到一个0均值和单位方差的正态分布。
2.规范化(Nomalize):
规范化给定数据集中的所有数值(或者分别对每个feature列处理)属性值,类属性除外。结果值默认在区间[0,1],但是利用缩放和平移参数,我们能将数值属性值规范到任何区间。[......]